Introduction to retrieval-augmented generation (RAG). Why data is the new gold while content is still king
Takeaways
- Definition of RAG: RAG combines large language models (LLMs) with external data sources, retrieving relevant documents to ground AI-generated responses in verified information.
- Advantages in Legal Tech:
- Improved Accuracy: By referencing authoritative legal content, RAG reduces AI "hallucinations," ensuring outputs are factually correct.
- Efficiency: Automates complex legal tasks like contract analysis and document summarization, saving time for legal professionals.
- Importance of Quality Data: The effectiveness of RAG depends on the quality of the data it retrieves; using trusted legal databases is crucial for reliable AI outputs.
- Mitigating AI Limitations: RAG addresses issues like biases and inaccuracies in LLMs by grounding responses in specific, relevant documents, enhancing reliability in legal applications.
Once ChatGPT took the world by storm, the legal industry was one of the first professional fields that began to reap its benefits. Why was that? Tapping into the large corpus of text found in documents, contracts, cases and other primary and secondary sources of material was tantamount to striking gold in the Generative AI (GenAI) race for legal research, writing, and more mundane legal tasks.
The use of GenAI backed by domain-specific retrieval-augmented generation (RAG) enables a rich level of nuance and expertise for specialized fields such as law. This is the single biggest differentiator for a more trustworthy and professional-grade legal AI assistant.
Context and other AI terms
Important concepts and terms need to be defined before even getting to the significance and implications of RAG’s application in legal work.
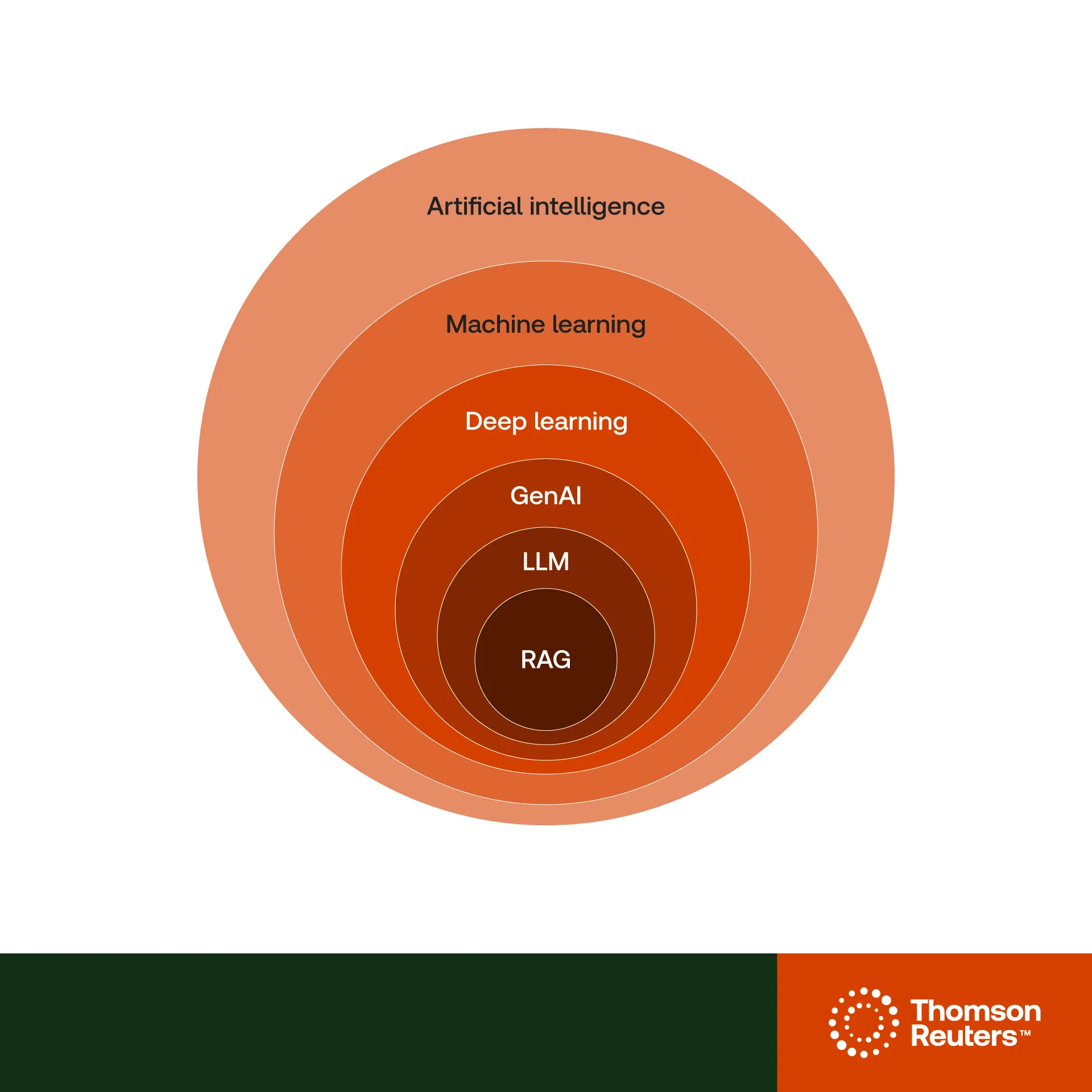
Artificial Intelligence (AI)
AI is the broader field of developing computer systems capable of human-like intelligence. AI itself is the idea that computers can simulate human intelligence. On the one hand, computers enable the artificial side. On the other hand, algorithms represent human intelligence and hence simulate or imitate intelligence.
Logical behavior, decisions, and rules are at the core of human intelligence. This is where it gets interesting for attorneys and legal professionals since they need to follow a set of rules and make logical decisions in order to practice law effectively.
Similarly, AI algorithms are designed to follow logical rules and make decisions based on data and patterns. This allows AI to perform tasks that would typically require human intelligence, such as problem-solving, learning, and decision-making.
Machine learning (ML)
Machine learning is a particular subset of AI that involves training models and computer algorithms to make predictions or decisions without rule-based programming. This allows AI to continuously learn and improve from ingested data to make more accurate decisions similar to how humans learn from experience.
Now to supervised vs. unsupervised learning. Supervised learning involves providing the model with labeled data and desired outcomes, while unsupervised learning involves allowing the model to identify patterns and make decisions on its own. Supervised learning is about predicting values and variables. Unsupervised learning is about unstructured data and making sense of the raw data.
Both approaches have their own advantages and are used in different scenarios depending on the type of data and desired outcome. We can see how and why this affects the legal profession and the debates around legal tasks and even work-product.
Deep learning
Deep learning is a subfield of machine learning that involves training artificial neural networks with many layers (deep neural networks) to perform tasks such as image and speech recognition.
Natural Language Processing (NLP)
Natural Language Processing (NLP) enables computers to comprehend, interpret, and create human language, bridging the gap between computers and human communication.
Generative AI (GenAI)
GenAI is any model that produces flexible outputs — images, text, audio, etc. — as opposed to discriminative AI which deals with classification and regression models. ML has allowed us to understand, hence learn, so GenAI can create. Therefore, GenAI is the technology based on the broader, previously defined terms that enables the ability to generate human-like text, images, and even videos.
Large Language Models (LLM)
LLMs form a bridge between our queries and what it generates. While traditional LLMs only deal with text inputs, more recent multimodal models can handle multiple input types like images, video, and audio.
LLMs are trained on large amounts of data — usually on billions of trainable parameters. They are built from deep learning and machine learning models and are made of complicated formulas that predict the next word.
Overall, LLMs have the potential to greatly assist with legal tasks by automating and expediting processes that would typically require human effort. However, it is important to carefully consider the training data and potential biases and hallucinations when implementing LLMs in legal settings.
Retrieval-augmented generation (RAG)
Finally, RAG is the processing of raw data that truly sets a professional-grade LLM apart from others. This process is called grounding in which an LLM is augmented with industry-specific data that is not part of the development process for mass market LLMs.
Rather than having the LLM answer a question based on its own memory, it first retrieves relevant documents from a search engine and then uses those documents as inputs to the LLM in order to ground the answer.
For the legal field, it means gathering and preprocessing legal documents, prompt engineering, and intense human evaluation to improve specific tasks such as contract analysis or legal document summarization. This allows for a more efficient and accurate analysis of legal documents, leading to potential time and cost savings for legal professionals.
Retrieval of gold-standard legal content
Content is indeed still king, and data is the new gold. However, it’s the quality of that data and how it’s managed that becomes the critical factor.
There are many legal research tools on the market using LLMs. However, legal tech specialists need to ask the right questions and understand just exactly what kind of content sources and training data its LLM retrieves for every query.
As a side effect of their training, LLMs often tend to please, and if they don’t know the answer offhand, they may make something up in an attempt to be helpful. RAG can mitigate this by providing useful context to help answer questions, similar to an open-book quiz, thereby grounding an LLM’s answer and reducing the risk of hallucinations.
Shang Gao
Lead Applied Scientist, TR Labs
Westlaw content
Westlaw has always been the standard for legal research because of its content and proprietary editorial enhancements like the West Key Number System and KeyCite.
In the West reporting system, an attorney-editor reviews each case published. The lawyer-editor finds and summarizes the legal points in the case. These summaries, known as headnotes, are placed at the beginning of the case and typically consist of a paragraph.
Each headnote is assigned a specific topic and key number, and they are organized in multi-volume books called Digests. These Digests act as subject indexes for the case law found in West reporters. It’s important to note that headnotes are editorial aids and do not serve as legal authority themselves.
For instance, AI-Assisted Research on Westlaw Precision focuses the LLM on the actual language of cases, statutes, and regulations. It doesn’t ask the LLM to generate answers based solely on the question asked but rather the content it searches. It finds the very best cases, statutes, and regulations to address the question, as well as the very best portions of those cases, statutes, and regulations.
Studies have shown that poor retrieval and/or bad context can be just as bad as or worse than relying on an LLM’s internal memory — just as a law student using outdated textbook will give wrong legal answers, an LLM using RAG without good sources will generate unreliable content. That’s why the Westlaw and CoCounsel GenAI solutions are so dependable — they are backed by the largest and most comprehensive legal libraries available.
Shang Gao
Lead Applied Scientist, TR Labs
Practical Law content
Practical Law provides trusted guidance, checklists and forms that help attorneys practice law effectively, efficiently, and ultimately with less risk.
The reliability of this data is dependent on the people responsible for its labeling, structure, and annotations.
The team of over 650 legal expert editors are highly qualified and have practiced at the world’s leading law firms, corporate law departments and government agencies. Their full-time job is to create and maintain timely, reliable, and accurate resources to ensure they have a great starting point with their legal matters such as new legal realities, legislative changes, and relevant practice areas.
Whether it’s a crisis, an unfamiliar matter, or an ever-evolving issue, they provide comprehensive insight and answers to your “how do I” questions.
RAG reliability
Yet even the gold standard of the most trusted and reliable sources of legal content falls short without a robust testing and benchmarking process. In other words, what constitutes a thoughtful and methodical process to ensure more trust, reliability, and accuracy?
Testing benchmarks
Our research products are composed of highly complex LLM flows and prompting techniques supported by the latest research ideas. In order to ensure our products are optimized and effective for any and all users, we need comprehensive benchmarks that cover all the use cases that lawyers may come across.
This is precisely why a Thomson Reuters benchmarking and evaluation team stressed the importance of both retrieval and generation components in legal AI systems.
For a RAG-based system, this means ensuring that the initial document retrieval is accurate and relevant, as it directly impacts the quality of the generated output. Legal tech specialists should therefore thoroughly analyze and weigh the benefits of both RAG and LLM components when considering legal-specific GenAI assistants.
For example, the Search a Database skill first uses various non-LLM-based search systems to retrieve relevant documents before the LLM synthesizes an answer. If the initial retrieval process is substandard, the LLM’s performance will be compromised.
Jake Heller
Head of CoCounsel, Thomson Reuters
CoCounsel’s Trust Team recognizes the subjective nature of legal tasks and the variability in what constitutes a correct answer. The best way to address this is embodied in their decision to not only test and benchmark, but also release performance statistics and sample tests.
Adapted from a keynote talk given by Casetext senior machine learning researcher Shang Gao at the 3rd International Workshop on Mining and Learning in the Legal Domain (MLLD-2023).

.avif)
.avif)